GIF僨僐乕僪張棟傪嶌傞嵺偵丄拲堄偟側偗傟偽偄偗側偄億僀儞僩
1. 廔椆僐乕僪偵棅偭偰丄夋憸僨乕僞偺廔傢傝傪敾抐偟偰偼偄偗側偄
GIF僨僐乕僪張棟偺拞偱儊僀儞偲側傞偺偼丄LZW埑弅偝傟偨晞崋壔僐乕僪傪撉傒崬傫偱丄僺僋僙儖偵揥奐偟偰峴偔張棟偱偡丅
杔偼嵟弶丄壓恾偺僼儘乕僠儍乕僩偺傛偆側曽朄偱丄張棟傪嶌惉偟傑偟偨丅
(仸愢柧傪娙扨偵偡傞偨傔偵丄嵶偐側揰偼丄僼儘乕僠儍乕僩撪偱偼徣棯偟偰偁傝傑偡丅)
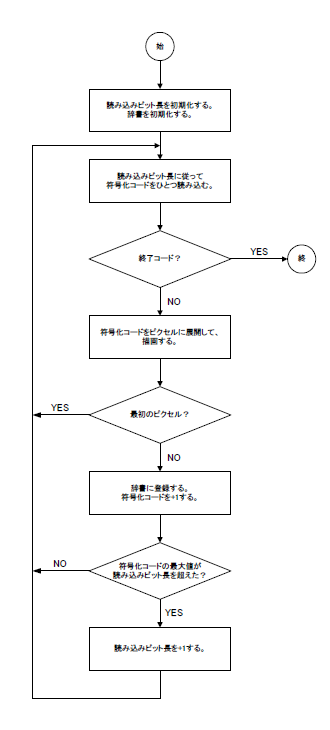
偙偺曽朄偱丄偨偄偰偄偺GIF僼傽僀儖偼僨僐乕僪偱偒傞偺偱偡偑丄婬偵僨僐乕僪偱偒側偄GIF僼傽僀儖偑敪惗偟偰偟傑偄傑偟偨丅
偨偲偊偽丄11亊6僺僋僙儖丒2怓僷儗僢僩偱丄夋憸慡懱傪僇儔乕0偱儀僞揾傝偟偨GIF僼傽僀儖傪僨僐乕僪偟傛偆偲偡傞偲丄乽僨乕僞晄懌乿偺尨場偱僨僐乕僪偵幐攕偟偰偟傑偄傑偡丅
惓偟偄GIF僼傽僀儖偱偁傞偵傕偐偐傢傜偢丄側偤乽僨乕僞晄懌乿偲敾抐偟偰偟傑偭偰偄傞偺偐丄挷嵏偡傞偨傔丄傑偢丄GIF僼傽僀儖偺撪梕傪HEX僄僨傿僞偱僟儞僾偟偰傒傑偟偨丅

忋恾偺拞偱丄椢怓傪晅偗偨晹暘偑丄LZW埑弅偝傟偨晞崋壔僐乕僪傪娷傓丄夋憸僨乕僞偺晹暘偱偡丅
夋憸僨乕僞偺晹暘偩偗傪敳偒弌偟偰丄愢柧傪壛偊偰傒傑偟偨丅

奺乆偺晞崋壔僐乕僪偼丄悢價僢僩偯偮偺戝偒偝偱丄傃偭偪傝媗傔崬傑傟偰偄傑偡丅
慜弎偺僼儘乕僠儍乕僩偺曽朄偱丄奺乆偺晞崋壔僐乕僪傪撉傒崬傫偩偲偒偵丄壗偑婲偒偰偄傞偐偺愢柧傪壛偊偰傒傑偟偨丅
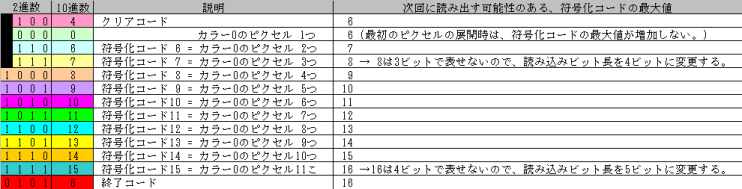
LZW夝搥傾儖僑儕僘儉偵廬偭偰丄晞崋壔僐乕僪傪撉傒弌偡偨傃偵帿彂傊偺搊榐傪峴偄丄師夞偵撉傒弌偡壜擻惈偺偁傞晞崋壔僐乕僪偺嵟戝抣傪丄1偢偮憹傗偟偰偄傑偡丅
晞崋壔僐乕僪15傪撉傒弌偟偨屻傕丄師夞偵撉傒弌偡壜擻惈偺偁傞晞崋壔僐乕僪偺嵟戝抣傪丄1憹傗偟偰16偲偟偰偄傑偡丅
16偼4價僢僩偱偼昞偣側偄偺偱丄師夞偺撉傒崬傒價僢僩挿傪5價僢僩偵曄峏偟偰偄傑偡丅
偲偙傠偑丄晞崋壔僐乕僪15偺屻偵偼丄廔椆僐乕僪偑4價僢僩偺挿偝偱奿擺偝傟偰偄偰丄偦傟埲崀偵偼夋憸僨乕僞偑懚嵼偟傑偣傫丅
僾儘僌儔儉偼丄5價僢僩暘偺撉傒崬傒傪峴偍偆偲偟傑偡偑丄4價僢僩暘偟偐撉傒崬傔偢丄乽僨乕僞晄懌乿偱幐攕偟偰偟傑偆偺偱偡丅
側偤丄廔椆僐乕僪偑丄5價僢僩偺挿偝偱側偔丄4價僢僩偺挿偝偱奿擺偝傟偰偄傞偺偱偟傚偆偐丅
LZW埑弅傾儖僑儕僘儉傪嵞妋擣偟偰傒傞偙偲偵偟傑偡丅
帪塉僄僲僉僆僾僩偝傫偺GIF僨僐乕僟僒儞僾儖僾儘僌儔儉夝愢偺拞偵偁傞丄乽LZW埑弅傾儖僑儕僘儉乿偺愢柧傪巊傢偣偰偄偨偩偒傑偟偨丅
愒帤偺売強偼丄杔偑捛婰偟偨僥僉僗僩偱偡丅
1.丂暥帤偑1暥帤偩偗偺岅傪慡偰搊榐偟偨帿彂傪梡堄偡傞丏
丂丂嵟弶偺1暥帤傪撉崬傫偱偦傟傪曄悢w偵擖傟傞丏
丂丂------ 儖乕僾奐巒 ------
2.1 1暥帤撉崬傫偱丆曄悢k偵擖傟傞丏
丂丂埑弅偡傋偒僨乕僞偑傕偆柍偄応崌丆3傊丏
2.2 曄悢w偺捈屻偵曄悢k偑懕偄偰偄傞暥帤楍傪曄悢wk偵擖傟傞丏偡側傢偪wk=w+k偲側傞丏
2.3 曄悢wk偑帿彂偵搊榐偝傟偰偄傞偐傪挷傋傞丏
2.4 wk偑搊榐偝傟偰偄傞応崌丗
丂丂2.1偵栠傞丏
2.5 wk偑搊榐偝傟偰偄側偄応崌丗
丂丂wk傪帿彂偵搊榐偡傞丏帿彂偺晞崋壔僐乕僪偺嵟戝抣偵傛偭偰丄彂偒弌偟價僢僩挿傪憹傗偡丏
丂丂w傪帿彂偺搊榐斣崋偱晞崋壔偡傞丏彂偒弌偟價僢僩挿偵廬偭偰丄晞崋壔僐乕僪傪彂偒弌偡丏
丂丂k傪w偵擖傟丆2.1偵栠傞丏
丂丂------ 儖乕僾廔椆 ------
3.丂嵟屻偵w偵岅偑巆偭偰偄傞応崌丗
丂丂w偵巆偭偰偄傞岅傪晞崋壔偡傞丏彂偒弌偟價僢僩挿偵廬偭偰丄晞崋壔僐乕僪傪彂偒弌偡丏
丂丂偙偺帪揰偱丆w偵擖偭偰偄傞岅偼帿彂偵搊榐偝傟偰偄傞偼偢側偺偱丆帿彂偺搊榐斣崋偱晞崋壔偱偒傞丏
丂丂偟偨偑偭偰丄帿彂偵搊榐偡傞張棟偼晄梫偱丄帿彂偺晞崋壔僐乕僪偺嵟戝抣偼曄傢傜偢丄彂偒弌偟價僢僩挿傕憹偊側偄丏
4.丂彂偒弌偟價僢僩挿偵廬偭偰丄廔椆僐乕僪傪彂偒弌偡丏
晞崋壔僐乕僪傪彂偒弌偡張棟偼丄2.5偲3.偺擇偐強偵偁傝傑偡丅
偄傑栤戣偲側偭偰偄傞GIF僼傽僀儖偺僨乕僞偱尵偆偲丄嵟弶偺僺僋僙儖乣晞崋壔僐乕僪14傑偱偼2.5嵟屻偺晞崋壔僐乕僪15偼3.偱彂偒弌偝傟傑偡丅
2.5偲3.偺堘偄偵拲栚偡傞偲丄
2.5偵偼丄帿彂偵搊榐偡傞張棟偲丄彂偒弌偟價僢僩挿傪憹傗偡張棟偑偁傝傑偡偑丄3.偵偼丄偦傟傜偺張棟偑偁傝傑偣傫丅
偮傑傝丄嵟屻偺晞崋壔僐乕僪傪彂偒弌偟偨屻丄師夞偵撉傒弌偡壜擻惈偺偁傞晞崋壔僐乕僪偺嵟戝抣偼曄壔偣偢丄彂偒弌偟價僢僩挿傕憹偊傑偣傫丅
LZW埑弅傾儖僑儕僘儉偵懳墳偟偰丄傕偆偄偪偳LZW夝搥傾儖僑儕僘儉傪峫偊偰傒傞偲丄奺乆偺晞崋壔僐乕僪傪撉傒崬傫偩偲偒偵丄埲壓偺傛偆偵張棟偡傞偺偑惓夝偲側傝傑偡丅
僾儘僌儔儉偼丄嵟屻偺僺僋僙儖偺揥奐帪傪摿暿埖偄偟偰丄晞崋壔僐乕僪偺嵟戝抣傪憹傗偝側偄傛偆偵偟側偗傟偽側傝傑偣傫丅
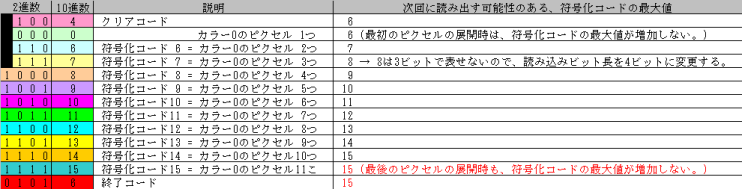
僾儘僌儔儉偼丄偳偆傗偭偰嵟屻偺僺僋僙儖偐偳偆偐傪敾抐偡傟偽椙偄偺偱偟傚偆偐丅
幚嵺偺偲偙傠丄忢偵揥奐偟偨僺僋僙儖悢傪悢偊偰偍偄偰丄夋憸慡懱偺僺僋僙儖傪揥奐偟偨偐偳偆偐偱敾抐偡傞曽朄偟偐偁傝傑偣傫丅
偄傑栤戣偲側偭偰偄傞GIF僼傽僀儖偺応崌丄11亊6僺僋僙儖偺夋憸偱偡偺偱丄僾儘僌儔儉偼丄崌寁66僺僋僙儖揥奐偟偨捈屻偺張棟傪摿暿埖偄偡傞偙偲偵側傝傑偡丅
奺乆偺晞崋壔僐乕僪偲夋憸偺僺僋僙儖偺懳墳傪恾偵昞偡偲丄晞崋壔僐乕僪15偑丄嵟屻偺僺僋僙儖偵懳墳偟偰偄傞偺偑傢偐傝傑偡丅
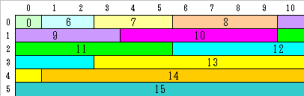
偲偙傠偱丄傛偔峫偊傞偲丄僾儘僌儔儉帺恎偑夋憸慡懱偺僺僋僙儖傪揥奐偟偨偐偳偆偐傪攃埇偟偰偄傞偺側傜偽丄廔椆僐乕僪偵棅傜側偔偰傕揥奐廔椆傪敾抐偱偒傑偡丅
傕偟丄夋憸慡懱偺僺僋僙儖傪揥奐偡傞慜偵丄廔椆僐乕僪傪撉傒弌偟偰偟傑偭偨傜丄僨乕僞偑夡傟偰偄傞偐僾儘僌儔儉偑娫堘偭偰偄傞傢偗偱偡丅
岞奐偝傟偰偄傞GIF僨僐乕僟偺僜乕僗傪偄偔偮偐挷傋偰傒偨偲偙傠丄乽廔椆僐乕僪傪撉傒弌偟偨傜懄僄儔乕乿偲敾抐偟偰偄傞傕偺偑懡偄傛偆偱偡丅
偨偩偟丄傕偟偐偡傞偲丄夋憸慡懱偺僺僋僙儖傪奿擺偡傞慜偵廔椆僐乕僪傪奿擺偟偰丄巆傝偼攚宨怓偲尒側偟偰偟傑偆傛偆側GIF僼傽僀儖偑懚嵼偡傞偐傕偟傟傑偣傫丅
幚嵺偵偦偺傛偆側GIF僼傽僀儖傪尒偨傢偗偱偼側偄偺偱偡偑丄偦偆偄偆僨乕僞偺奿擺曽朄偑OK側偺偐NG側偺偐丄GIF巇條彂偐傜敾抐偡傞偙偲偑偱偒傑偣傫偱偟偨丅
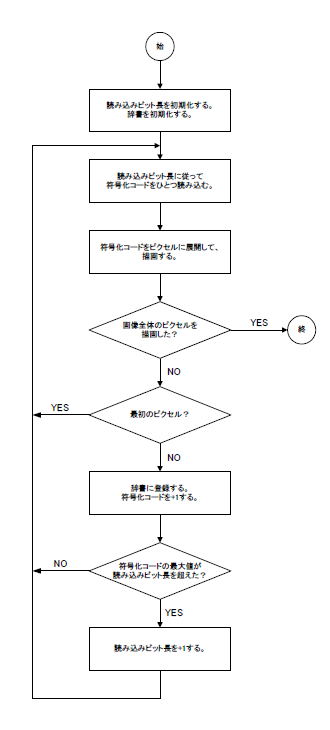
埲忋傪傑偲傔傞偲丄GIF僨僐乕僪張棟偺僼儘乕僠儍乕僩偼丄壓恾偺傛偆偵側傝傑偡丅
(仸愢柧傪娙扨偵偡傞偨傔偵丄嵶偐側揰偼丄僼儘乕僠儍乕僩撪偱偼徣棯偟偰偁傝傑偡丅)
Sun Apr 12 20:48:20 JST 2009 Naoyuki Sawa (nsawa@piece-me.org)